数据可视化基础——可视化流程
本系列「数据可视化基础」文章共三篇,介绍可视化中最基础、最重要的一些概念、理论。这篇为第一篇,主要介绍可视化流程 (opens in a new tab),另两篇则主讲数据模型 (opens in a new tab)和视觉编码 (opens in a new tab)。 原文地址:http://geekplux.com/2017/01/01/basics-of-data-visualization-the-process-model (opens in a new tab)
很多人认为数据可视化非常简单,无非是输入几组数据,生成简单的条形图、直线图等等。然而,这未免有点管中窥豹。其实数据可视化大致可分为信息可视化、科学可视化和可视化分析三大类,刚才提到的简单图表只是信息可视化中最常见的几种。一旦数据量增大,可视化目标改变,可视化系统的复杂度可能就会超出我们的想象。本文中涉及到的可视化流程模型适用于信息可视化和科学可视化。可视化分析的流程模型略有不同,本文暂时不进行讨论。
通用的可视化流程
做任何事都有一个流程,可视化也不例外。
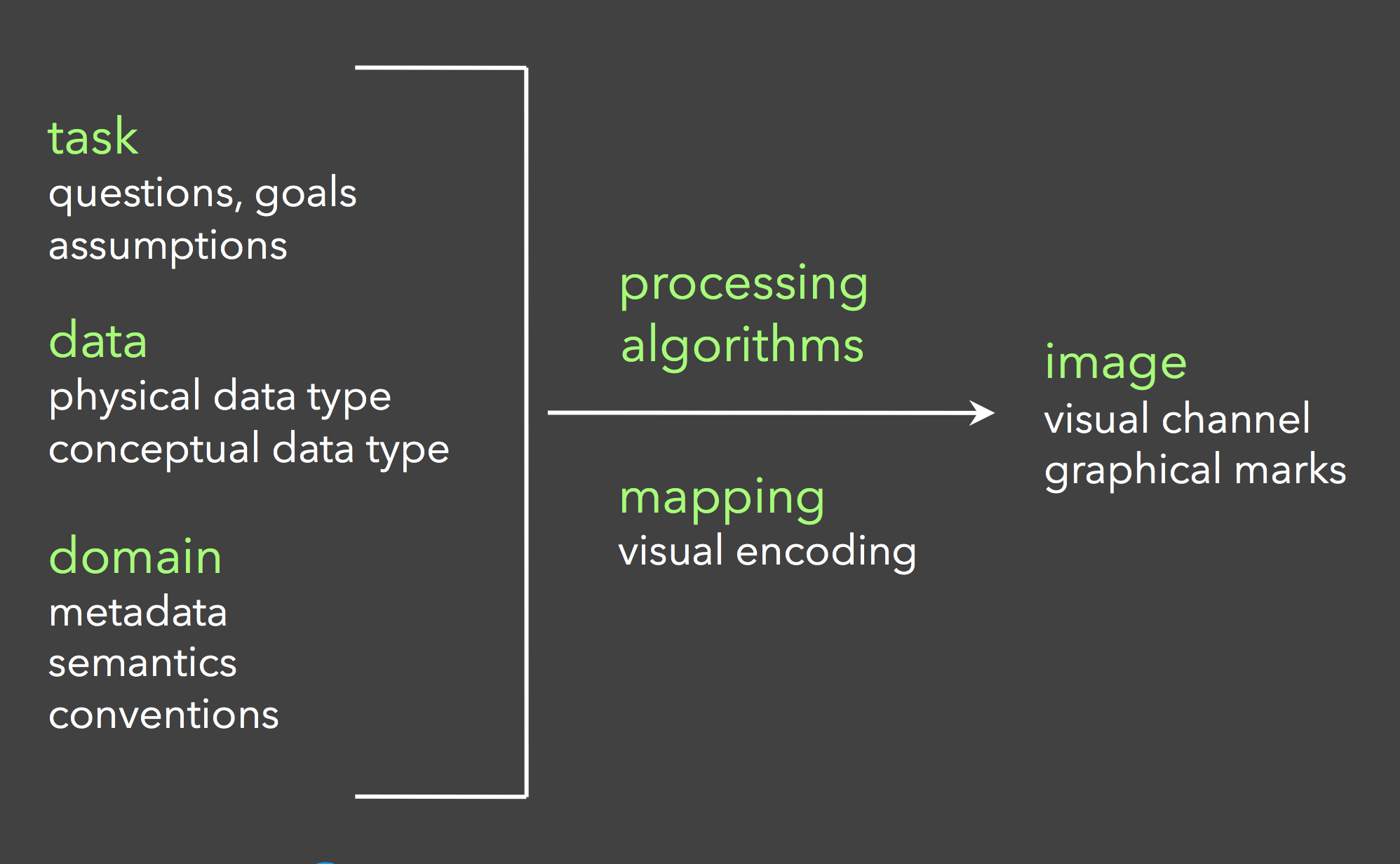
一图以蔽之。可视化整体可分为三步:分析 - 处理 - 生成。
一、分析
进行一个可视化任务时,我们首当其冲的当然是要分析,分析又分为三部分:任务、数据、领域。
首先我们要分析我们这次可视化的出发点和目标是什么。我们遇到了什么问题、要展示什么信息、最后想得出什么结论、验证什么假说等等。数据承载的信息多种多样,不同的展示方式会使侧重点有天壤之别。只有想清楚以上问题,才能确定我们要过滤什么数据、用什么算法处理数据、用什么视觉通道编码等等。
其次我们要分析我们的数据,这是至关重要的一步。因为每次可视化任务拿到的数据都是不同的,数据类型、数据结构均有变化,数据的维度也可能成倍增加。抽象的数据类型如何对应现实中的概念,不同的数据类型如何进行视觉编码,这些我们在下一篇数据模型 (opens in a new tab)中进行介绍。
最后我们针对不同的领域,也要进行相应的分析。毕竟术业有专攻,可视化的侧重点要跟着领域做出相应的变化。
二、处理
处理可以分为两部分:对数据的处理和对视觉编码的处理。
1.数据处理
在可视化之前我们要对数据进行数据清洗、数据规范、数据分析。
数据清洗和规范是必不可少的步骤。首先把脏数据、敏感数据过滤掉,其次再剔除和我们目标无关的冗余数据,最后调整数据结构到我们系统能接受的方式。
数据分析中最简单的方法当然是一些基本的统计方法,如求和、中值、方差、期望等等;复杂的方法有数据挖掘种的各种算法,这是又一个领域了,在此不赘述。
最后的可视化结果中我们肯定不可能把所有的数据统统展示出来,于是又涉及到包括标准化(归一化)、采样、离散化、降维、聚类等数据处理的方法,这些概念之后可以单独写篇文章来介绍。
2.设计视觉编码
视觉编码的设计是指如何使用位置、尺寸、灰度值、纹理、色彩、方向、形状等视觉通道,以映射我们要展示的每个数据维度。这里看不懂没关系,第三篇视觉编码 (opens in a new tab)中会详细介绍。
三、生成
这个阶段基本上就是把之前的分析和设计付诸实践,在制作或写代码过程中,再不断调整需求、不断地迭代(有可能要重复前两步),最后产出我们想要的结果。
其它可视化流程
线性模型
1990 年 Robert B. Haber 和 David A. McNabb 提出的数据可视化流程已经非常先进:
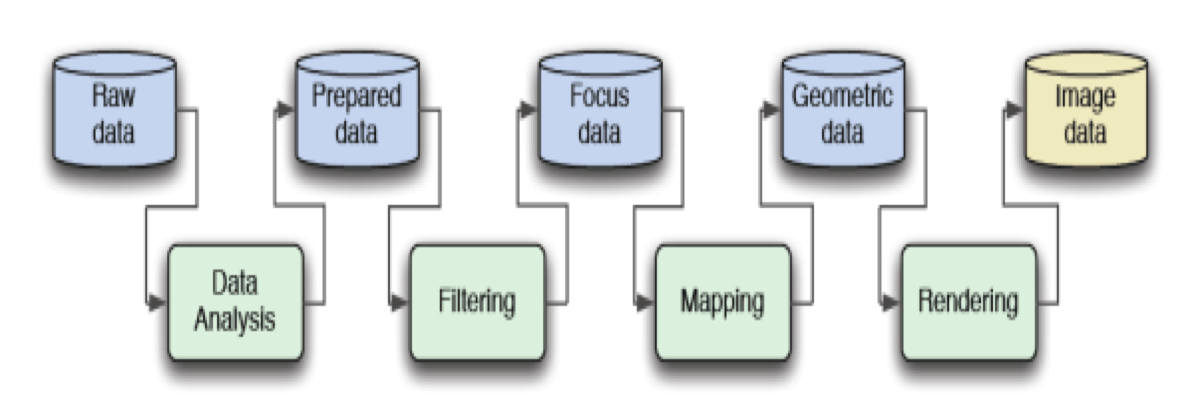
这个处理模型非常先进,整个流程是线性的。它把数据分成五大阶段,分别要经历四个流程,每个过程的输入是上一个过程的输出。从图上看非常直观,很好理解。
嵌套模型
另一种模型是嵌套模型:
![Munzner T. A Nested Process Model for Visualization Design and Validation[J]. IEEE Transactions on Visualization & Computer Graphics, 2009, 15(6):921-8.](https://geekpluxblog.oss-cn-hongkong.aliyuncs.com/basics-of-data-visualization/nested-model.png?x-oss-process=style/zip)
嵌套模型的上半部分基本上就是我们之前说的分析、处理两步,下半部分是对可视化结果的各类验证。本质上就是一个验证加迭代的过程。我们知道很多事都不是一蹴而就的,需要不断迭代,所以有人提出了循环模型。
循环模型
![Stolte C, Hanrahan P. Polaris: a system for query, analysis and visualization of multi-dimensional relational databases[C]// IEEE Symposium on Information Visualization. 2000:5-14.](https://geekpluxblog.oss-cn-hongkong.aliyuncs.com/basics-of-data-visualization/cyclical-model-1.png?x-oss-process=style/zip)
![Wijk J J V. The Value of Visualization[C]// Visualization, 2005. VIS 05. IEEE. 2005:11-11.](https://geekpluxblog.oss-cn-hongkong.aliyuncs.com/basics-of-data-visualization/cyclical-model-2.png?x-oss-process=style/zip)
循环模型的两张图其实都是把线性模型首尾连起来,从图上看一目了然。
目前应用最广的模型
![Card S K, Mackinlay J D, Shneiderman B. Readings in information visualization: using vision to think[M]// Readings in information visualization :. Morgan Kaufmann Publishers, 1999:647-650.](https://geekpluxblog.oss-cn-hongkong.aliyuncs.com/basics-of-data-visualization/best-process-model.png?x-oss-process=style/zip)
对比之前的线性模型,其实也很类似,不过其在最后加入了用户交互的部分,且让每个步骤都变成了循环的。这是目前应用最广的可视化流程模型,后继几乎所有著名的信息可视化系统和工具都支持、兼容这个模型。
总结
纵观以上提到的各类模型,都非常类似,本质上还是离不开分析 - 处理 - 生成三步,所以掌握第一张图就可以了,以不变应万变。文中多次提到视觉编码、数据处理等概念,我们在接下来的两篇数据模型 (opens in a new tab)和视觉编码 (opens in a new tab)介绍。欢迎各位在我博客文末留言讨论(如果看不到评论框可能是因为你没有科学上网)。
参考文献
- [1]陈为 沈则潜 陶煜波. 数据可视化[M]. 电子工业出版社, 2013. (opens in a new tab)
- [2]浙江大学-陈为、巫英才数据可视化课程 (opens in a new tab)
- [3]Haber, R. B. and McNabb, D. A. Visualization idioms: A conceptual model for scientific visualization systems, 1990.
- [4]Munzner T. A Nested Process Model for Visualization Design and Validation[J]. IEEE Transactions on Visualization & Computer Graphics, 2009, 15(6):921-8.
- [5]Stolte C, Hanrahan P. Polaris: a system for query, analysis and visualization of multi-dimensional relational databases[C]// IEEE Symposium on Information Visualization. 2000:5-14.
- [6]Wijk J J V. The Value of Visualization[C]// Visualization, 2005. VIS 05. IEEE. 2005:11-11.
- [7]Card S K, Mackinlay J D, Shneiderman B. Readings in information visualization: using vision to think[M]// Readings in information visualization :. Morgan Kaufmann Publishers, 1999:647-650.
- [8]cse512 data visualization (spring 2016) (opens in a new tab)