D3 force layout and WebGL integration
原文地址:https://geekplux.com/2017/06/27/d3-force-and-webgl-integration
D3 是目前最流行的数据可视化库,WebGL 是目前 Web 端最快的绘制技术。由于性能问题的局限,将两者结合的尝试越来越多(如),本文将尝试用 D3 的力导向图 和 Three.js 和 PixiJS 结合。全文阅读完大概 5 分钟,因为你重点应该看代码。
做数据可视化时,必然会考虑性能的问题。早前数据可视化都是用 Qt 等 GUI,后来逐渐迁移到了迅猛发展的浏览器上展示,Web 的性能问题成了大多数可视化的局限,尤其是在三维可视化,或数据量特别大的时候。现在主流的 Web 可视化技术为三种:SVG、Canvas 和 WebGL,难易程度和性能如下图:
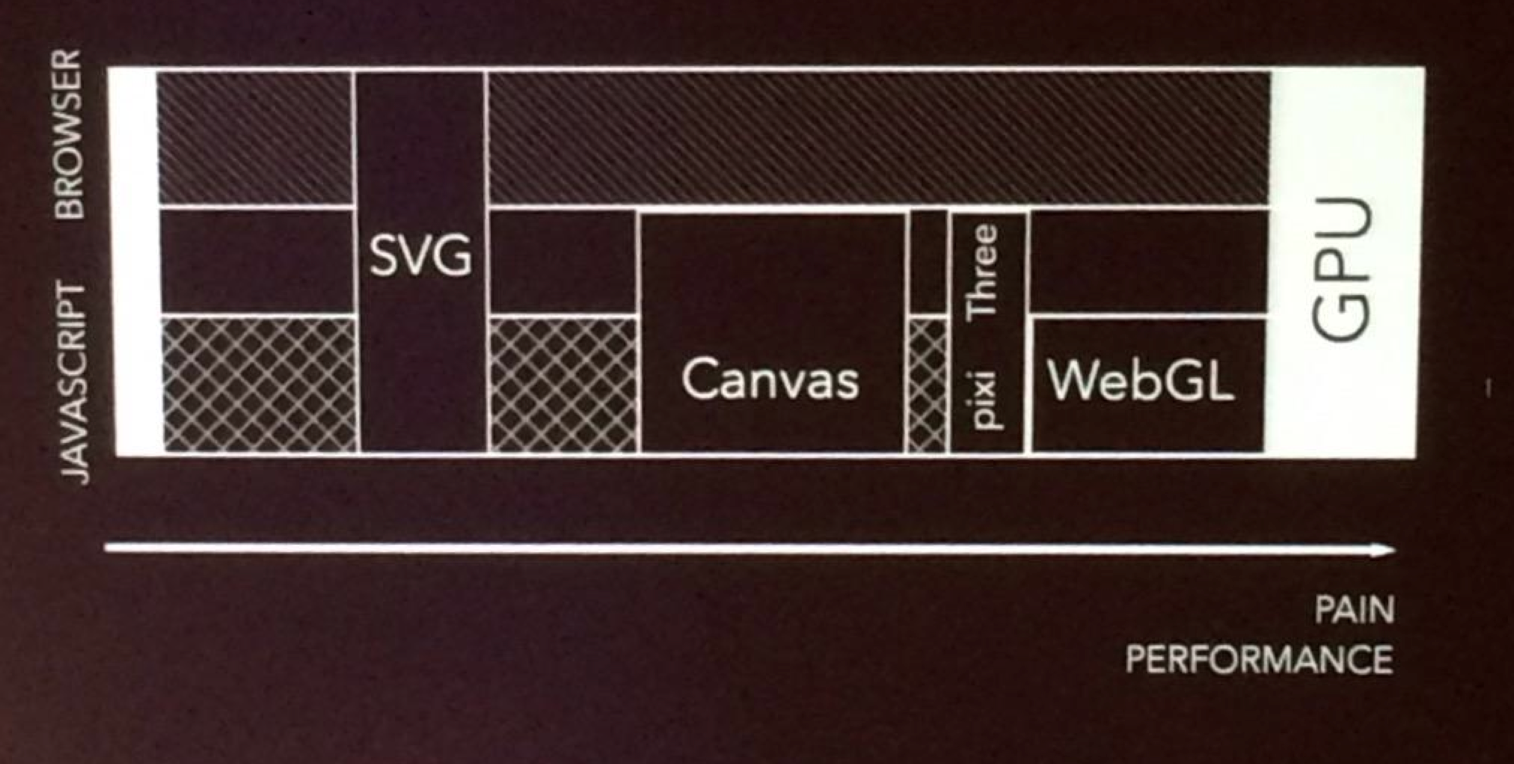
SVG 的优点很多,编辑简单,交互便捷,灵活性极高,业内成熟的可视化工具(如 d3)都是用的 SVG。但是每个 SVG 都是一个 DOM 元素,随着它的数量上来之后,交互开始慢的难以忍受。这是因为每当修改一个 DOM 对象,只要这个对象在文档里,接着在浏览器里就会发生两个动作,一个叫 Reflow(重排,就是重新排版),另一个叫 Repaint(重绘,就是重新渲染页面)。这两个动作不一定都会发生,但如果被修改的 DOM 当前可见的话,那么就会先重排,后重绘。绘制性能上 canvas 和 SVG(DOM 元素)应该差不多,但前者可以省掉重排过程,因此性能更高。然而,WebGL 的性能更胜一筹,因为 WebGL 使用 GPU 加速渲染,GPU 在大规模计算方面有绝对优势(图像处理、深度学习都在用,显卡已经卖疯了)。例子:用 WebGL 绘制 200000 个点的动画
WebGL 虽然威力无穷,但是写起来比较痛苦,画个三角形大致要 100 行代码。所以很多人对 WebGL 进行了封装。上面图中提到的两个 Three.js 和 PixiJS 是目前最流行的两款 WebGL 库,当然还有新兴的 regl 在今年的 OpenVis 上大放异彩。本文尝试用前两者和 d3-force 结合(项目代码在此),后面如果有时间的话,我会把使用 regl 和原生 WebGL 的例子也补充进去(我知道这是个 flag)。
正文
首先我们要知道什么是力导向图和如何使用 d3-force。d3 4.0 之后,作者将其模块化,force 这个模块是基于 velocity Verlet 实现了物理粒子之间的作用力的仿真,常用于网络或关系结构数据。即你把网络中的节点想象成一个个粒子,它们之间互相有作用力,所以不停的拉扯,直到趋于一个稳定状态,具体可以看我 demo 中可视化出来的样子。
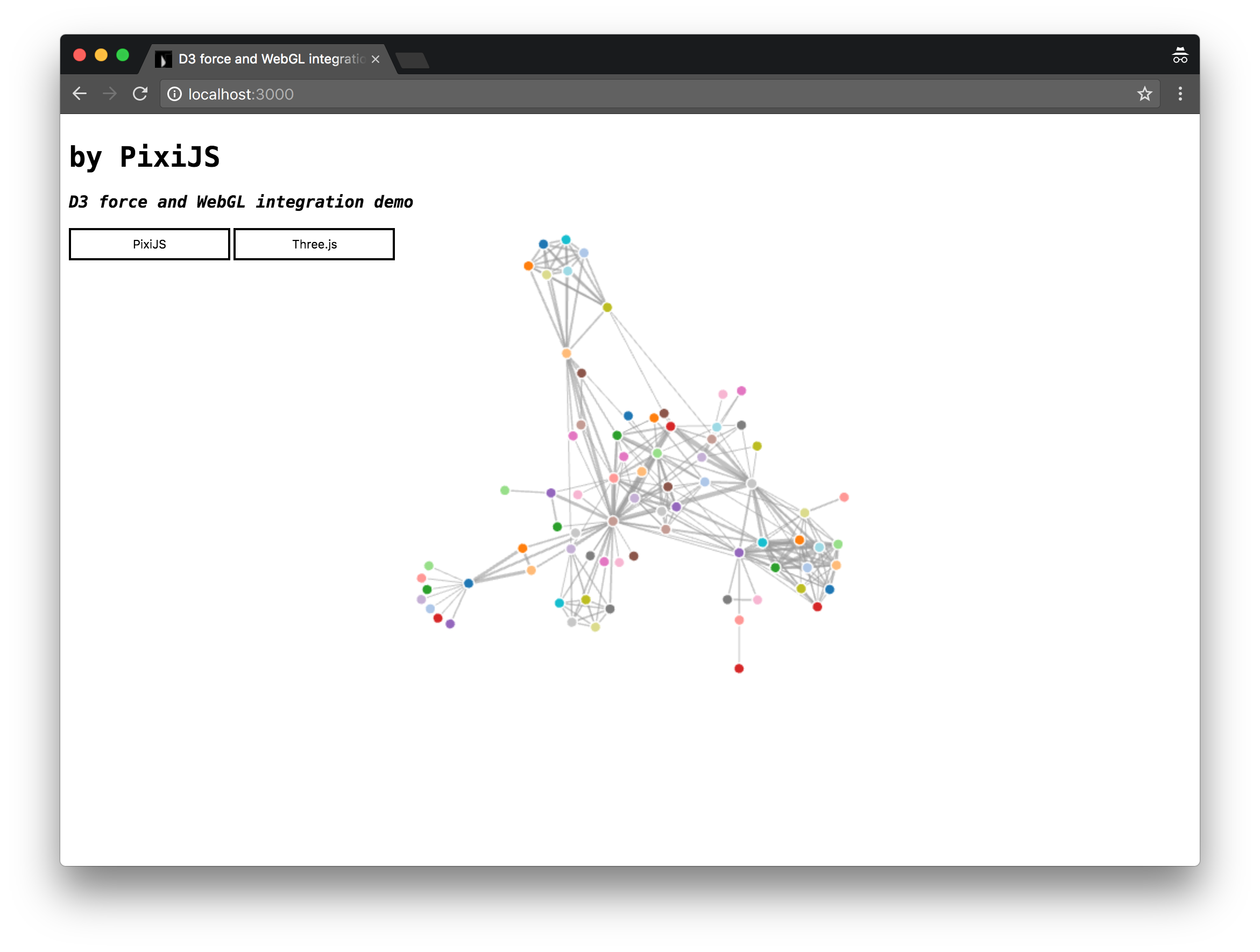
仔细看 demo 中的源码可以发现,用 three.js 和用 pixi.js 实现起来非常类似,其中有关力导向图的关键代码是下面几句:
const simulation = d3.forceSimulation() // 创建一个作用力的仿真,但此时还没启动
.force('link', d3.forceLink().id((d) => d.id)) // 为边之间添加 Link 型作用力
.force('charge', d3.forceManyBody()) // 指定节点间的作用力类型为 Many-Body 型
.force('center', d3.forceCenter(width / 2, height / 2)) // Centering 作用力指定布局围绕的中心
d3-force 提供了五种作用力,分别是 Centering、Collision、Links、Many-Body、Positioning。此时我们已经创建好带有各种力的仿真器了,接下来需要启动它:
simulation
.nodes(data.nodes) // 根据 data.nodes 数组来计算点之间的作用力,相当于不停计算节点的 xy 坐标
.on('tick', ticked) // 每次 tick 调用 ticked
simulation.force('link')
.links(data.links) // 根据 data.links 数据计算边之间的作用力
至此一个力导向图的仿真就开始了,那么怎么把这些节点和边显示出来呢?让我们继续看源码,以 three.js 为例:
const scene = new THREE.Scene()
const camera = new THREE.OrthographicCamera(0, width, height, 0, 1, 1000)
const renderer = new THREE.WebGLRenderer({alpha: true})
renderer.setSize(width, height)
container.appendChild(renderer.domElement) // container 这里是 document.body
在 Three.js 中展示场景需要具备三要素:场景、照相机、渲染器。照相机就相当于我们的眼睛,它对着渲染好的场景就相当于把场景成像到了相机中,这里的照相机我们用的是平行投影相机,渲染器我们使用的是 WebGL 渲染器。设置好渲染器的大小,把它添加到页面的元素上,相当于添加了一个 <canvas> 元素。接下来,我们生成每个节点和边的样子:
data.nodes.forEach((node) => {
node.geometry = new THREE.CircleBufferGeometry(5, 32)
node.material = new THREE.MeshBasicMaterial({ color: colour(node.id) })
node.circle = new THREE.Mesh(node.geometry, node.material)
scene.add(node.circle)
})
data.links.forEach((link) => {
link.material = new THREE.LineBasicMaterial({ color: 0xAAAAAA })
link.geometry = new THREE.Geometry()
link.line = new THREE.Line(link.geometry, link.material)
scene.add(link.line)
})
套路都一样,都是先建一个几何体,然后设置材质的样式,添加到场景中就好了。接下来只要在刚才提到的 ticked 这个回调函数中把节点和边的坐标更新一下就好了:
function ticked () {
data.nodes.forEach((node) => {
const { x, y, circle } = node
circle.position.set(x, y, 0)
})
data.links.forEach((link) => {
const { source, target, line } = link
line.geometry.verticesNeedUpdate = true
line.geometry.vertices[0] = new THREE.Vector3(source.x, source.y, -1)
line.geometry.vertices[1] = new THREE.Vector3(target.x, target.y, -1)
})
render(scene, camera)
}
是不是比想象的简单多了?如果以上有什么地方看不懂,说明你可能对 Three.js 不是很了解,不过没关系,它的文档写的很好,入门很快。希望这篇文章能给你带来一些帮助,做了点微小的贡献,很惭愧 :)