Vega-Lite: A Grammar of Interactive Graphics
在 InfoVis 2016 上,UW 交互数据实验室 提出了一种新的交互数据可视化语法——Vega-Lite,获得了今年的 best paper,本文将根据其论文从多个角度介绍 Vega-Lite。论文地址。原文地址:https://geekplux.com/2016/11/02/vega-lite-a-grammar-of-interactive-graphics
什么是 Vega-Lite
简而言之,Vega-Lite 是一种数据可视化的高级语法,能够快速定义一些基本的交互式数据可视化。
如果你听说过 Vega,那么光看 Vega-Lite 的名字就不难想到它们的关系。Vega-Lite 就是编译成 Vega 的更高级图形语法。
如下图所示,只要右边寥寥数行代码,就能定义一个散点图:

为什么要提出 Vega-Lite
首先,Vega-Lite 的目标是:
- 通过一种规范来快速的表达你的可视化设计。
- 提供了简洁的语法和图元便于你快速切换设计。
以前的东西做不到吗?其实也不是做不到,只是在有些方面还有很大的提升空间,Vega-Lite 就是在这个方向上很大的一步棋:
- 低等级的可视化语法有更高的自由度,但往往高等级的可视化语言更受偏爱,主要因为其简洁,能快速做出东西,而且能生成低等级的语法供二次开发(Vega-Lite 可以编译成 Vega,而且所有代码都是 JSON 格式)。
- 低等级的可视化语言没法提供现成的可视化方案(得你自己设计),而高等级的可以直接搜索或推断出适合你的可视化方案,支持在线查看效果(比如用 vega-lite 配套的 Voyager)。
- 从交互方面来说,现有的高级语法在交互方面比较局限,而低等级语法可能为了定制化还得自己去处理事件回调(例如 D3),这对非专家很不友好且很容易出错。而 Vega-Lite 直接提供更简洁更具表现力的交互(一两行代码就能定义一个交互操作)。
为了实现以上的这些愿景,Vega-Lite 主要通过以下方式做出努力:
- Algebra 用于将单个 view 合成多 view
- Selection 用于交互选择判定
- Transform 对数据、交互操作转换
- Compiler 编译成 vega 语言,可供二次开发
接下来说说它怎么具体实现上面这四个概念的。
Vega-Lite 的具体语法
可以从两个方面分开介绍,分别是图形方面和交互方面。
Vega-Lite 的具体语法——图形方面
View 视图
首先,Vega-Lite 定义一个图形为一个 Unit,所以 Unit 是 Vega-Lite 里图形的最小单位。Unit 的定义是:
unit := (data, transforms, mark-type, encodings)
- data 用来说明数据的来源,支持 JSON 格式和 CSV 格式
- transform 定义了如何对原始输入数据进行处理
- mark 指定了可视化图形
- encoding 定义数据到可视化图形的映射规则
可视化中视觉通道的设计非常重要,所以其中,encoding 是比较重要的。
encoding := (channel, field, data-type, value, functions, scale, guide)
每个 Unit 可以通过一些 operators 变成 View,而 View 又可以通过一些 operators 变成复合的 View。
所以可以这么理解,你每个 operator 的单位是一个视图(可以是 Unit,也可以是 View),而一个 operator 的输出又可以作为下一个 operator 的输入,进而可以形成一个嵌套视图。
Operators 操作
刚才提到了 operators,你可以把一个 operator 理解成该以何种方式来整合视图。Vega-Lite 一共提供了四种 operators,分别是 Layer、Concatenation、Facet、Repeat。
Layer
Layer 很好理解,就是字面意思,将每个 View 重叠;
layer([unit1, unit2, ...], resolve)
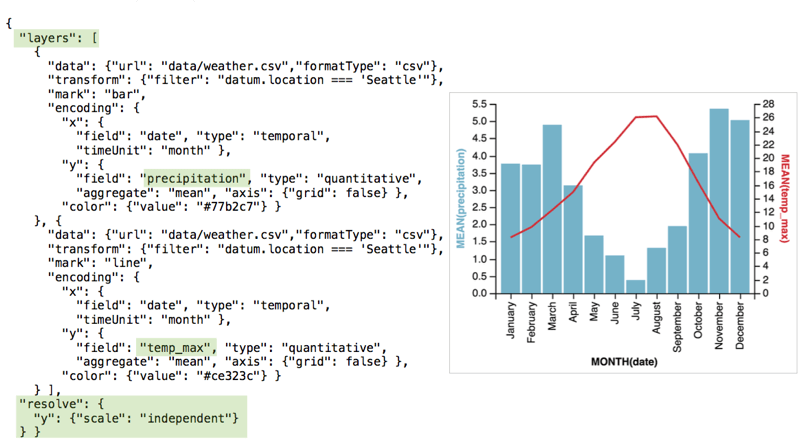
Concatenation
Concatenation 是将多个单视图水平放置或垂直放置;
hconcat([view1, view2, ...], resolve) vconcat([view1, view2, ...], resolve)
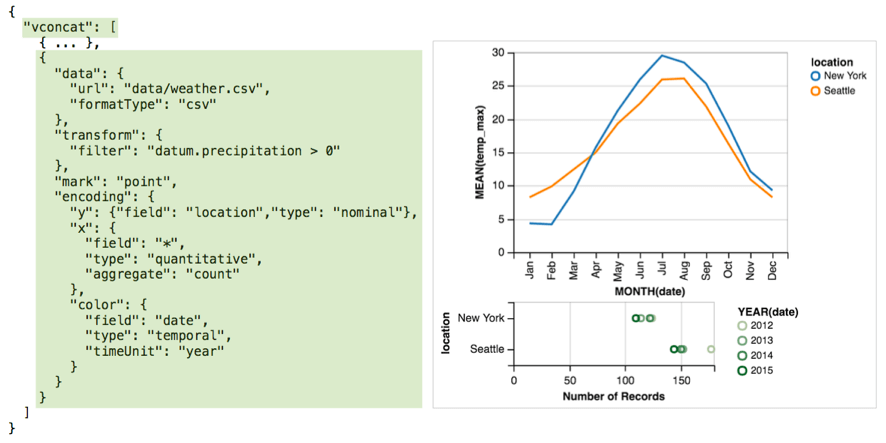
Facet
Facet 是将多个单视图根据数据中的某个 field 进行排布;
facet(channel, data, field, view, scale, axis, resolve)
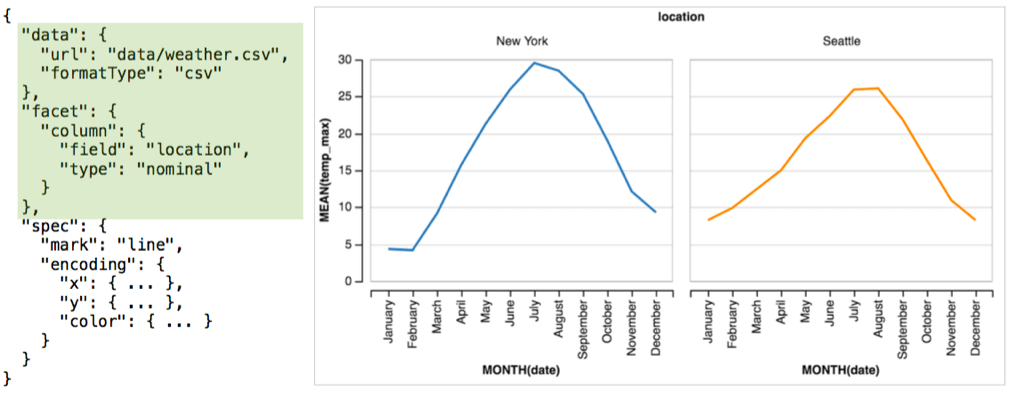
Repeat
Repeat 也很好理解,重复放置视图。
repeat(channel, values, scale, axis, view, resolve)
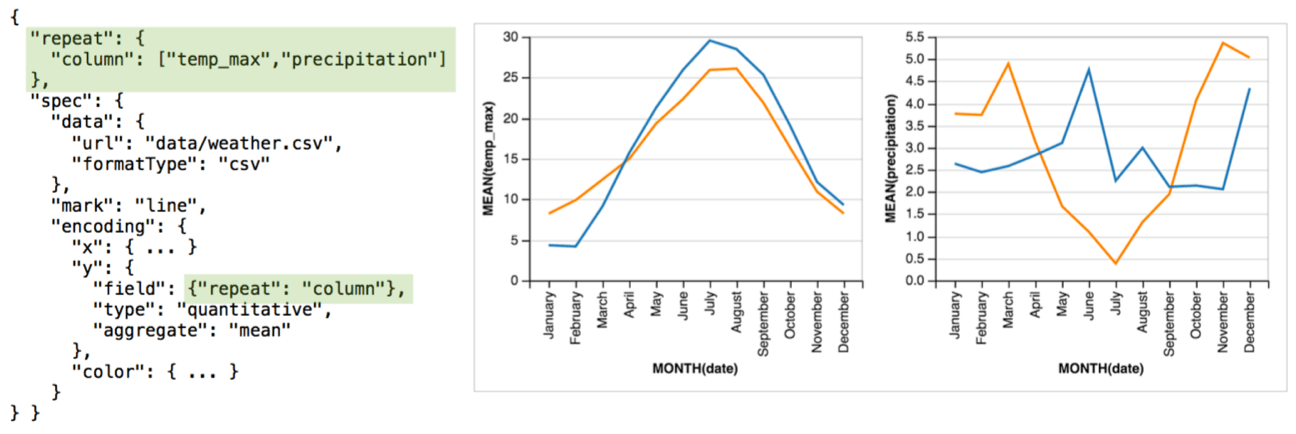
Vega-Lite 的具体语法——交互方面
任何交互中,选择一直是最重要的一个概念,所以 Vega-Lite 的所有交互也都围绕一个概念 —— Selection。首先看 Selection 的定义:
selection := (name, type, predicate, domain|range, event, init, transforms, resolve)
- name: 属性名
- type: point, list, intervel
- predicate: 决定符合条件的最小集合(判定哪些东西被选进来)
- event: 事件如何定义
- transform: 操作已选择的元素
其中 transform 又最为重要,它定义了已选择之后的操作。这些操作可以进行随机的组合,且用户不需要定义操作之间的先后顺序,因为具体的顺序由编译器定义。
Vega-Lite 目前提供的交互操作一共有 5 种,分别是:project(fields, channels)、toggle(event)、translate(events, by)、zoom(event, factor)、nearest()。
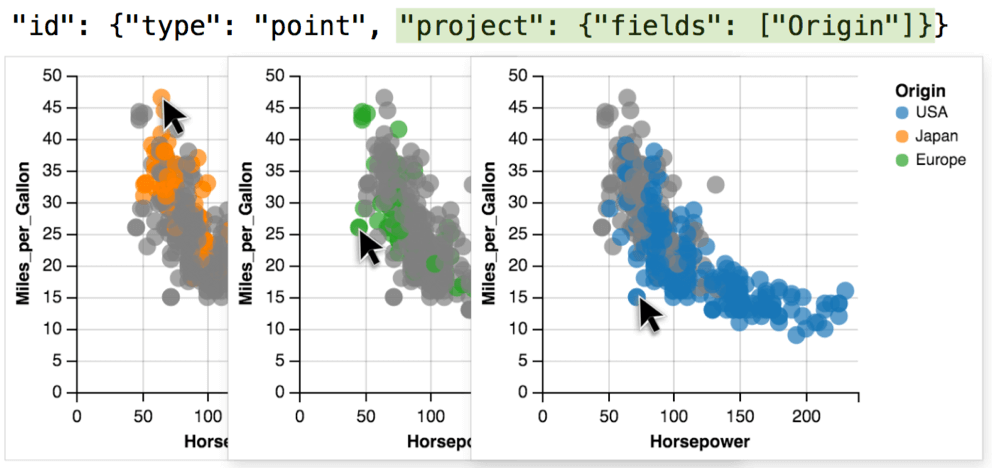
Project
Project 用来重定义判定函数 predicate。
Toggle
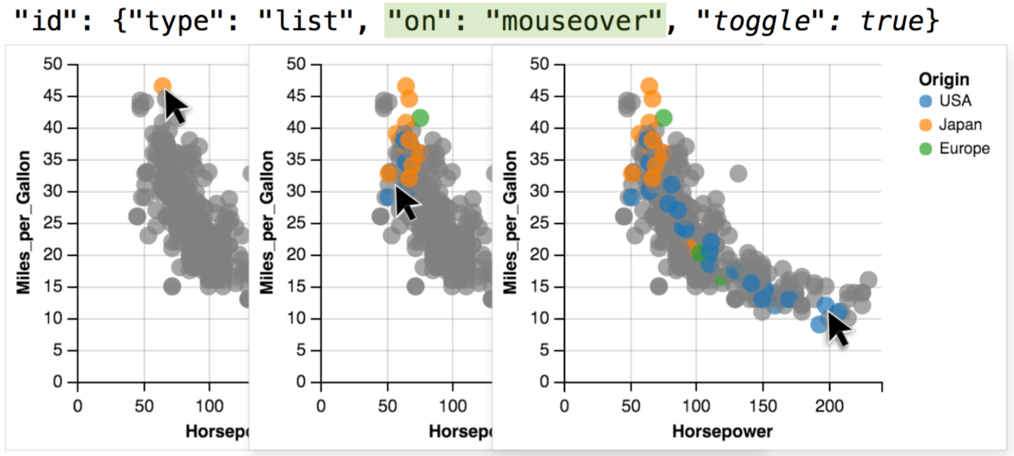
Toggle 表示按下 shift 键,可以在之前交互结果上,继续进行交互。
Translate
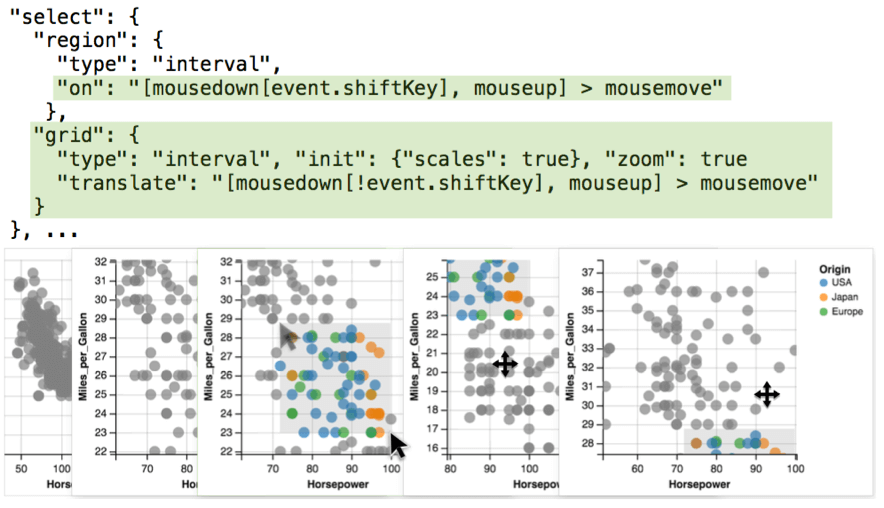
Translate 用于改变交互事件的判断
Zoom 和 Nearest
- Zoom 操作主要用户视图的缩放
- Nearest 操作,会将整个视图根据元素的位置分割成 Voronoi 图,然后将距当前交互的元素最近的元素选择出来
其他交互
if-then-else
简单的条件判断逻辑。
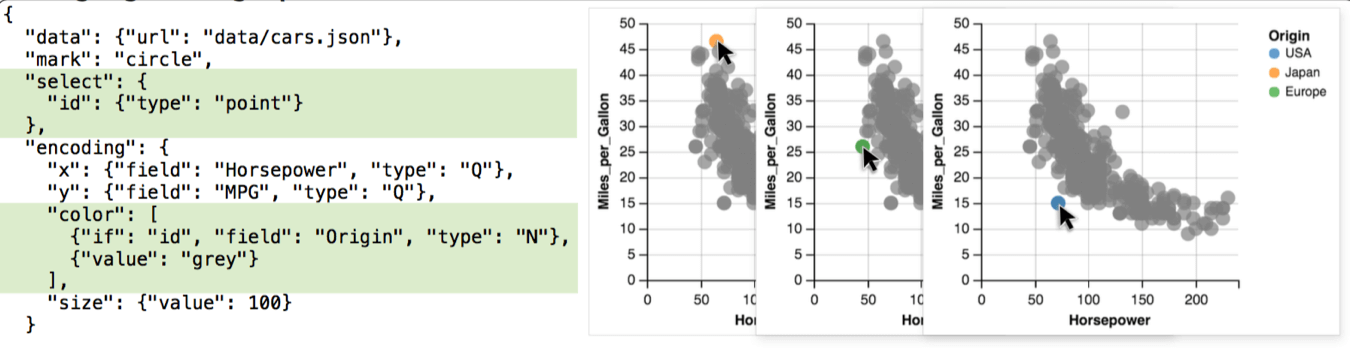
把选择的数据作为另一个 view 的输入
上文也说到过,可以理解成视图的嵌套,也可以用作多视图协作。
根据选择的数据设置的比例尺
结合上一点,就可以把一个视图作为另一个视图的拓展。例如下图的 Overview + Detail 模式。
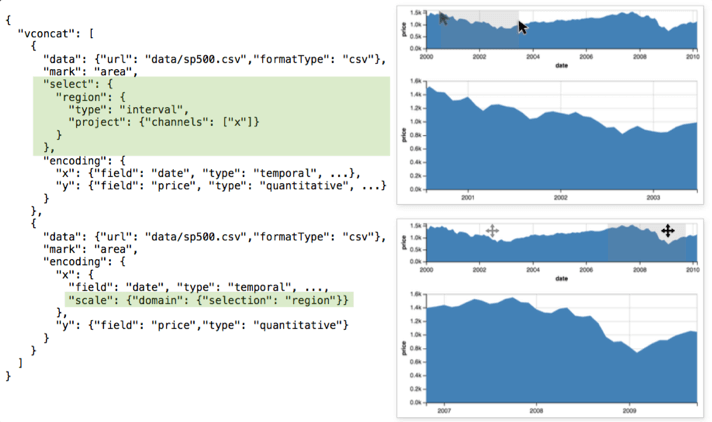
以上三个交互情形都支持与或非逻辑
多视图交互中的歧义
单视图中的交互,很可能在多视图中引发歧义。例如,在散点图矩阵中,如果在一个矩阵中进行 brush,其他的矩阵怎么配合协作?于是 Vega-Lite 又定义了四种交互协作模式,分别是 single、independent、union、intersect。
- 默认是 single,用户在某个视图中进行交互,其他视图不会做出响应。
- 其次是 independent,每个视图中的交互互不影响。
- union 求并集,是指只要在多视图中任意一个子视图选中的部分,就被算作选中。
- intersect 求交集,是指只有在多视图中都选中的部分,才被算作选中。
Vega-Lite 编译器
Vega-Lite 虽然也是用 JSON 写,但它可以编译成更低级的 Vega。其中它的编译器面临两个难点:
两个难点
- 数据结构不对应
- 由于 vega-lite 省略了很多细节设定,所以得编译器自己计算
四个步骤
编译器用四个步骤解决了以上两个难点。
- 语法分析,消除歧义
- 建立 vega-lite 和 vega 数据结构间的联系
- 组合、优化数据结构,去除冗余
- 汇编所有的元素
Vega-Lite 局限性
Vega-Lite 目前虽然已经发布,但依旧在紧锣密鼓的开发,主要是因其现在还没有达到其理想的效果,在以下两方面还有局限性:
- 生成的可视化结果依赖于当前 Vega-Lite 的实现(未来可能会通过解释器层面解决,而不是编译器)
- 本身固有的模式(通过 predicate function 抽象来解决)
总结
可视化在时下越来越重要,越来越多的行业需要对数据进行展示,而可视化的专家又少之又少,所以很需要一款像 Vega-Lite 一样,简单,智能的系统快速地实现可视化。这可能是可视化工具未来发展的方向 —— 快速实现,快速替换可视化方案,快速展示,接下来再进行二次开发,进而多次迭代。
由此可见 Vega-Lite 前景很大,不过可能还需要再沉淀、开发一段时间,我们拭目以待吧。
参考文献
- Satyanarayan, A., Moritz, D., Wongsuphasawat, K., & Heer, J. (2016). Vega-Lite: A Grammar of Interactive Graphics. IEEE Transactions on Visualization and Computer Graphics, 2626(c), 1–1. http://doi.org/10.1109/TVCG.2016.2599030